
식단 기록 application
목차
- 프로젝트 소개
- 기존 앱들의 문제점
- 해결방법
- System Architecture
- 구현 기능 Demo
- OCR로부터 영양소 양을 매칭하는 알고리즘 동작 과정
1. 프로젝트 소개
현재 존재하는 식단 관리 앱들의 핵심적인 기능과 목적은 사용자가 평소에 먹는 음식들을 기록하여 권장량만큼의 영양소를 섭취할 수 있도록 하는 것이다. 본 프로젝트는 이런 앱들이 공통적으로 갖고 있는 문제점을 해결하고, 차별화된 기능을 추가하는 것이다.
- 회원가입 시 사용자의 목표, 성별, 체중, 체지방량 등을 고려하여 하루동안 섭취해야 하는 영양소 양 추천
- 사용자가 먹은 제품의 영양성분표를 촬영하면 OCR로 인식하여 섭취한 영양소 양 기록
- 카카오톡 OAuth로 회원가입 및 로그인
2. 기존 앱들의 문제점
- 기존에 존재하는 앱들은 제품을 직접 검색하거나, 바코드를 찍어서 제품을 인식한 후 DB에 있는 제품 정보를 바탕으로 영양소 섭취량을 기록
- 인기가 없거나 새로 출시된 제품의 경우 DB에 존재하지 않는 경우가 있음
- 사용자가 직접 정보를 입력하면 DB에 제품이 추가되는 앱들이 존재하는데, 잘못된 정보가 기록되는 경우가 많음
3. 해결방법
영양성분표에 표기된 정보를 OCR로 인식하여 식단을 기록한다면, DB에 존재하지 않거나 잘못된 데이터가 저장되어 있는 문제점을 해결할 수 있을 것이라 판단하였다.
4. System Architecture
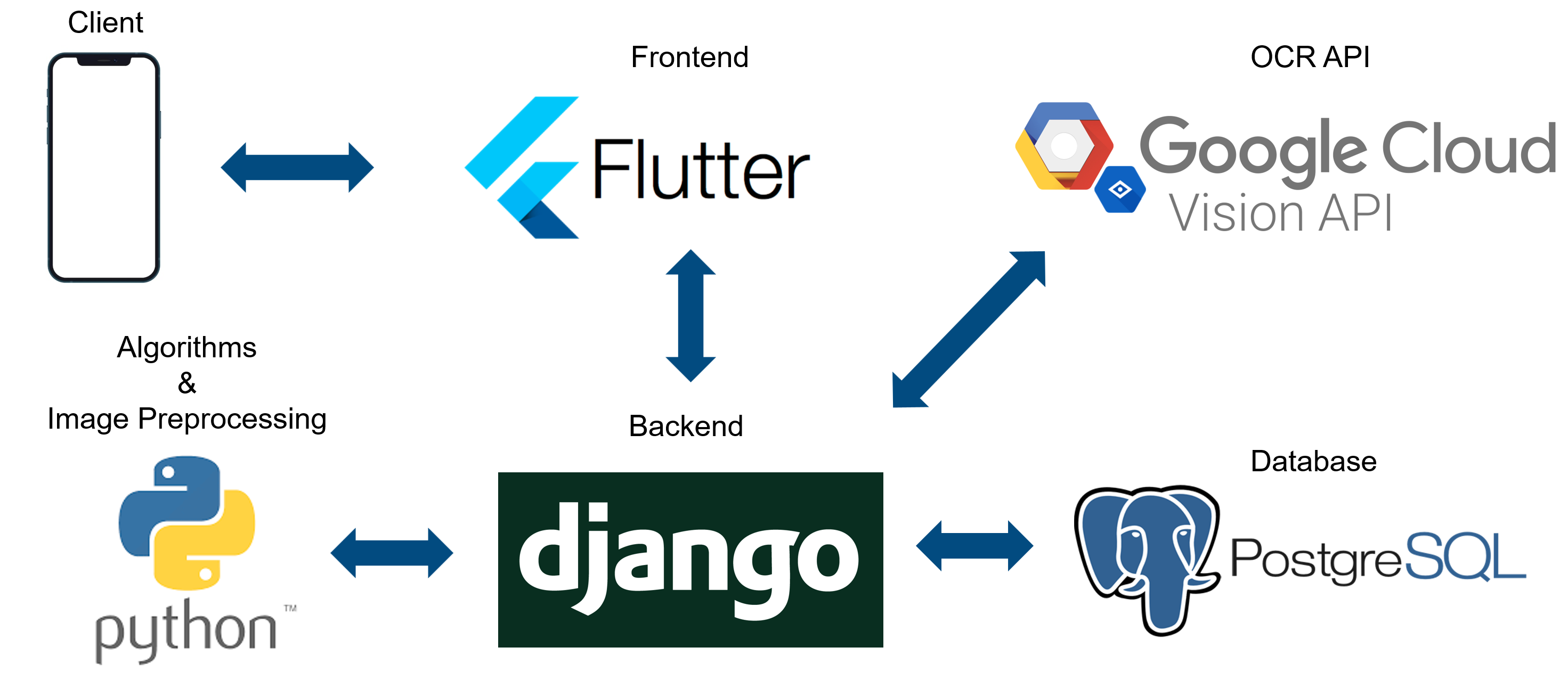
Frontend Framework – Flutter
한 학기 내에 Android, iOS에서 모두 사용할 수 있는 앱 제작이 목표이다 보니 cross-platform framework를 사용하기로 하였다. 가장 많이 사용하는 Flutter와 React-Native 중에서 최종적으로 Flutter를 사용하게 된 이유는, 사용자들에게 식단 관련 정보를 보여주는 데 최적화된 우리만의 디자인을 사용하기 위함이다. 우리가 사용하고자 하는 독특한 디자인 구현을 위해서는, 화면에 나타나는 거의 모든 UI를 native os가 아닌 Dart가 렌더링하는 Flutter를 사용하는 것이 React-Native 보다 유리하다고 생각했다.
Backend Framework – Django
OCR을 활용하여 영양 성분 정보를 정확히 추출해내기 위해서는 사진에 대한 전처리가 필요하다. 사진 전처리에는 파이썬 라이브러리를 활용할 계획인데, Node js와 같이 다른 언어로 된 framework를 사용하면 외부 script를 실행하는 데 overhead가 발생할 것으로 예상되었다. 따라서 파이썬 기반의 framework인 Django를 채택하였다.
Database – PostgreSQL
Django에서 공식적으로 지원하는 데이터베이스는 모두 RDBMS 계열이다. MongoDB와 같은 NoSQL도 별도의 연동 과정을 통해 사용할 수는 있지만, 공식적으로 지원하고 있지는 않아서 안정성이 떨어진다고 알려져 있다. 따라서 꼭 NoSQL 과 같이 다른 구조를 가진 데이터베이스를 사용해야 하는 것이 아니라면, 공식적으로 지원하고 있는 데이터베이스를 사용하는 것이 권장된다. 추가적으로 이번 프로젝트에서 저장해야 하는 데이터는 뒤에서 더 자세히 다루겠지만, 테이블 구조를 사용하는 것이 적합하다고 판단했기에 PostgreSQL을 사용하였다.
Image Preprocessing – Python
앞서 언급했듯이 OCR을 활용하여 영양 성분 정보를 정확히 추출해내기 위해서는 사진에 대한 전처리가 필요하다. 파이썬에는 이미지 처리와 관련하여 많은 라이브러리들이 존재하고, OpenCV와 같은 라이브러리는 C/C++ 기반으로 동작하기 때문에 매우 빠르다는 장점이 있다. 따라서 이러한 장점을 이용하기 위해 이미지 전처리 과정에서는 파이썬을 사용하기로 하였다.
OCR – Google Cloud Vision API
이미지 전처리를 제대로 진행해도, OCR이 정확하게 되지 않으면 소용이 없다. 따라서 OCR API를 선택하는 데 있어서 가장 중요하게 여겼던 것은 OCR 정확도였다. 한글에 대해 안정적인 정확도를 내는 API에는 Google Cloud Vision, Naver Clova 크게 두 가지가 있다. 이 둘의 정확도 차이는 크지 않지만, Google Cloud Vision API가 저렴하면서도 응답 속도가 빠르다고 알려져 있기에 Google Cloud Vision을 사용하게 되었다.
5. 구현 기능 Demo
Kakao 계정으로 회원가입 & 로그인
- Kakao 계정으로 회원가입 및 로그인을 진행할 수 있다.
- 회원가입 시 사용자의 정보(나이, 성별, 키, 몸무게, 식단 목표, 평소 활동량, 근육량, 체지방률)을 바탕으로 사용자에게 알맞은 영양 섭취량을 계산한다.
OCR를 활용한 식단 기록
- 사용자가 먹은 제품의 영양성분표를 촬영하면 OCR로 제품의 영양 정보를 인식한다.
- 사용자로부터 섭취한 제품의 수량을 입력받는다.
- 위의 정보로부터 사용자가 섭취한 영양소를 계산하여 기록한다.
- 만약 잘못된 영양소 정보가 존재한다면, 사용자가 수정할 수 있다.
기록된 식단을 바탕으로 사용자가 얼마나 더, 또는 덜 먹어야 하는 지 표시
- 사용자가 회원가입 시 입력했던 정보를 바탕으로 계산한 목표 식단과 오늘 하루동안 섭취한 식단을 비교하여 보여준다.
- 권장 섭취량을 초과하여 섭취한 영양소가 있다면 빨간색으로 표시된다.
- 권장 섭취량만큼 먹지 못한 영양소가 있다면 얼마나 더 먹어야 하는 지 표시한다.
6. OCR로부터 영양소 양을 매칭하는 알고리즘 동작 과정
(1) Image Preprocessing
이미지 전처리는 정확한 OCR을 위해 필요하다. 영양성분표의 일부 글자가 그림자로 인해 잘 보이지 않는 경우가 가끔 있고, 비닐이나 캔 등의 재질로 만들어진 제품들은 빛 반사에 의해 글자가 가려지는 경우가 생긴다. 추가적으로, 사용자가 사진을 수평에 맞게 찍지 않고 틀어서 찍더라도 텍스트 인식이 제대로 되도록 하기 위해, skew correction을 진행하였다.
Denoising
따라서, 우선 그림자나 빛과 같은 noise을 제거하기 위해 gaussian blur denoising을 사용하였다. Denoising이 적용되기 전후 사진은 아래와 같으며, 불필요한 그림자나 빛 반사 영역이 없어진 것을 확인할 수 있다.


Skew Correction
틀어서 찍힌 사진은 우선 가로로 된 선들을 찾은 후, x축 기준으로 틀어진 각도의 평균만큼 사진을 회전시켜 수평을 맞추었다. 사진에 존재하는 가로 선들을 찾기 위해서는 사진에 존재하는 edge를 찾는 과정이 선행되어야 하며, 이를 위해서는 canny edge detection을 사용하였다. 이후 hough line transform을 통해 사진에 존재하는 선들을 찾았다. Hough line transformation은 OpenCV 라이브러리에 존재하는데, cv2.HoughLines()와 cv2.HoughLinesP() 두 가지가 있다. 둘의 가장 큰 차이점은 직선임을 판단하기 위해 검사하는 점의 개수이다. 전자는 모든 점에 대해 계산을 하기 때문에 시간이 오래 걸리지만, 후자는 임의의 점을 이용하여 직선을 찾기 때문에 속도가 빠르다. 따라서 후자를 통해 사진에 존재하는 선들을 찾았다. X축을 기준으로 하였을 때 45° 보다 작은 각도로 기울어진 선들을 가로 선으로 추정하고, 이들의 평균 각도만큼 사진을 회전시켰다. 결과는 아래와 같다.
아래 그림은 왼쪽부터 Denoising 결과, Canny Edge Detection 결과, Hough Line Transform 결과, Rotation 결과




(2) 영양 성분 매칭
위치 기반 추출 알고리즘
이미지 전처리 후, 영양성분표에 존재하는 각 영양소의 양을 파악하기 위해 Google Cloud Vision API를 사용하여 사진에 있는 텍스트를 추출하였다. Google Cloud Vision API는 응답으로 텍스트 뿐만 아니라 각 단어의 bounding box 위치까지 제공하기 때문에, bounding box의 위치를 기반으로 각 영양소 양을 매칭하기로 하였다. 아래와 같이 가로로 된 영양성분표의 경우에는 세로 좌표를 비교함으로써, 세로로 된 영양성분표는 가로 좌표를 통해 영양성분 양을 매칭하였다.
영양성분표에 있는 영양소 양은 실제 양인 g, 그리고 영양성분에서 차지하는 비율 % 두 가지가 있다. g에 대응되는 숫자는 영양소 단어의 옆에(가로형 성분표인 경우) 있는 단어 4개를 합친 다음, regular expression을 통해 첫 번째 ‘g’ 앞에 나오는 숫자로 판단하였다. 옆에 있는 단어 4개를 보는 이유는 아래 왼쪽 그림과 같이 ‘25g’이라는 문자열이 ‘25’, ‘g’으로 분리되어 검출될 수도 있고, ‘25g’ 하나로 검출될 수도 있기 때문이다. 추가적으로 ‘25g 8%’가 아닌 ‘8% 25g’으로 배치되어 있는 영양성분표 존재 가능성을 염두에 두어, ‘8’, ‘%’, ‘25’, ‘g’, 4개의 단어를 포함시킨 것이다.
세로형 성분표인 경우에는 아래 오른쪽 그림과 같이 아래에 있는 2개의 숫자 중, 옆에 ‘g’라는 문자가 있는 숫자로 매칭하였다.
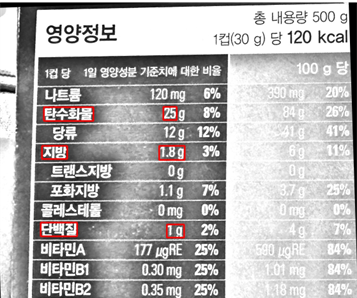
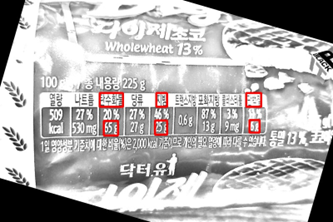
이 방법을 사용했을 때 일반적인 영양성분표에서는 문제가 없다. 그러나 아래와 같이 영양성분 정보가 다른 줄에 걸쳐서 배치된 경우 위치 기반 알고리즘으로 추출되지 않는다는 점이다. 이를 해결하기 위해, 문자열 기반으로 영양성분을 추출하는 알고리즘을 추가하였다.


문자열 기반 추출 알고리즘
위치 기반 추출 알고리즘이 문제가 되었던 부분은 텍스트 중간에 줄 바꿈이 일어나기 때문이다. 따라서 줄 바꿈이 일어나더라도 각 줄들을 하나의 문자열로 합치게 된다면, 영양 성분와 양을 차례대로 매칭할 수 있을 것으로 예상되었다.
Google Cloud Vision API OCR의 응답에 들어있는 단어들의 순서는 이미지 상에서 사람이 글을 읽는 순서와 동일하다. 따라서 응답에 들어있는 모든 단어들을 하나의 배열로 합치면 줄 바꿈이 일어나더라도 다음 단어들을 보면서 정보 해석이 가능하다.
하지만 영양성분 정보를 파악하는 데 필요한 단어들만 해석하면 되므로, 모든 단어를 배열에 포함시킬 필요는 없다. 따라서 해당 단어가 영양소 단어의 2글자 이상의 substring이거나, 알파벳 ‘g’가 포함되어 있거나, 숫자가 포함되어 있으면 단어 배열에 추가하도록 하였다.
위의 왼쪽 영양성분표에 대해 단어 필터링을 하였을 때, 다음과 같은 배열이 생성된다.
[‘B2’, ‘1일’, ‘10kcal,’, ‘탄수화물’, ‘2g(1%),’, ‘단백’, ‘0g(0%),’, ‘지방’, ‘0g(0%),’, ‘나트륨’, ‘0mg(0%),’, ‘500’, ‘mg(500%),’, ‘비타민B10.36’, ‘mg(30%),’, ‘비타민B2’, ‘0.42’, ‘mg(30%),’, ‘비타민B6’, ‘0.45’, ‘mg(30%),’, ‘비타민B12’, ‘0.72’]
생성된 배열에서의 영양소 양 매칭 과정은 위치 기반 추출 알고리즘에서 regular expression을 사용하여 매칭하는 과정과 동일하다.
알고리즘 동작 순서
위치 기반 추출 알고리즘이 줄 바꿈 문제를 해결하지 못해 문자열 기반 추출 알고리즘을 사용한 것처럼, 문자열 기반 알고리즘 역시 세로형 영양성분표가 주어지면 영양소 양을 매칭하지 못한다. 즉, 두 가지 알고리즘이 모두 필요하다. 따라서 문자열 기반으로 먼저 영양소 양 매핑을 시도하고, 파악하지 못한 영양소들에 대해서는 추가적으로 위치 기반 알고리즘을 사용하였다.