
Vision transformer
An Image is Worth 16x16 Words : Transformers for Image Recognition at Scale
Vision transformer(ViT)로 불리는 모델에 대한 논문이다.
자연어 처리에서 transformer가 높은 성능을 보이면서 transformer 구조를 컴퓨터 비전에 도입하기 위한 여러 시도가 있었다.
그러나 대부분의 모델들은 기존의 cnn의 구조는 유지하되, attention mechanism만 추가하는 방식으로 설계되었다.
이 논문은 cnn 구조에서 벗어나, transformer architecture만을 사용하여 SOTA를 달성한 것이 특징이다.
Patch Embedding
Patch embedding은 transformer encoder에서 이미지에 대한 정보를 잘 처리할 수 있도록 이미지를 전처리하는 과정이다.
NLP에서 transformer encoder는 일반적으로 vector로 embedding된 단어들 간의 score를 계산하여 어떤 단어들이 중요한 지 판단한다.
이러한 encoder를 이미지에 사용하기 위해 ViT에서는 이미지를 이미지 patch들로 나누고, 각 패치에 위치 정보를 추가해 encoder에 넣는다.
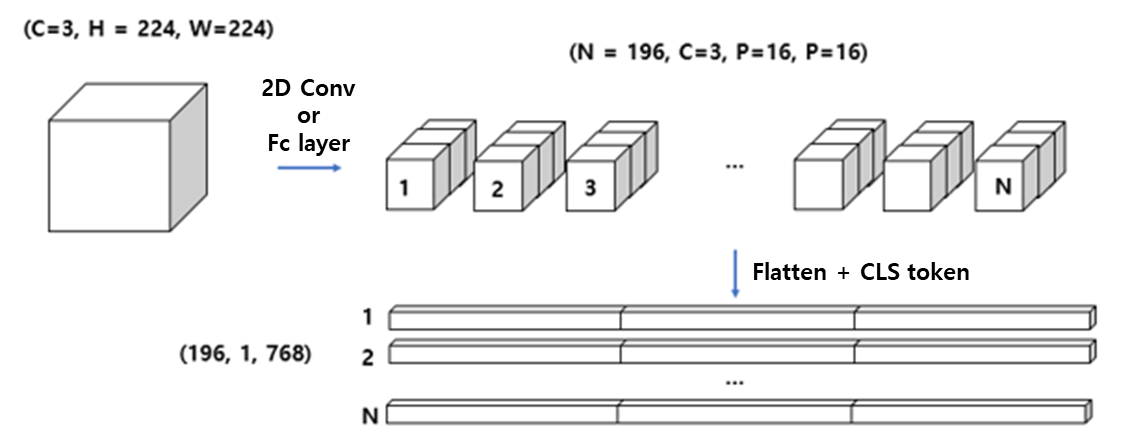
위 그림과 같이 이미지가 $\mathbf{\text{x}} \in \mathbb{R}^{H \times W \times C}$ 이고 patch의 크기를 $P$라 한다면, $N=HW/P^2$개의 patch들이 만들어질 것이다.
.png)
하나의 이미지 패치는 $P^2$개의 픽셀을 담고 있는데, 이를 flatten한 후 projection하여 (1, 768) 크기의 벡터를 만든다. 이렇게 만든 벡터에 element-wise로 positional embedding을 더하면 하나의 patch에 대한 patch embedding이 만들어진다.
Positional embedding은 NLP에서 단어의 위치를 나타내는 것과 같이 이미지 상에서 patch의 위치 정보를 담는다고 할 수 있다.
Encoder
Encoder에서는 각 패치에 대한 정보를 self-attention 메커니즘을 통해 추출한다.
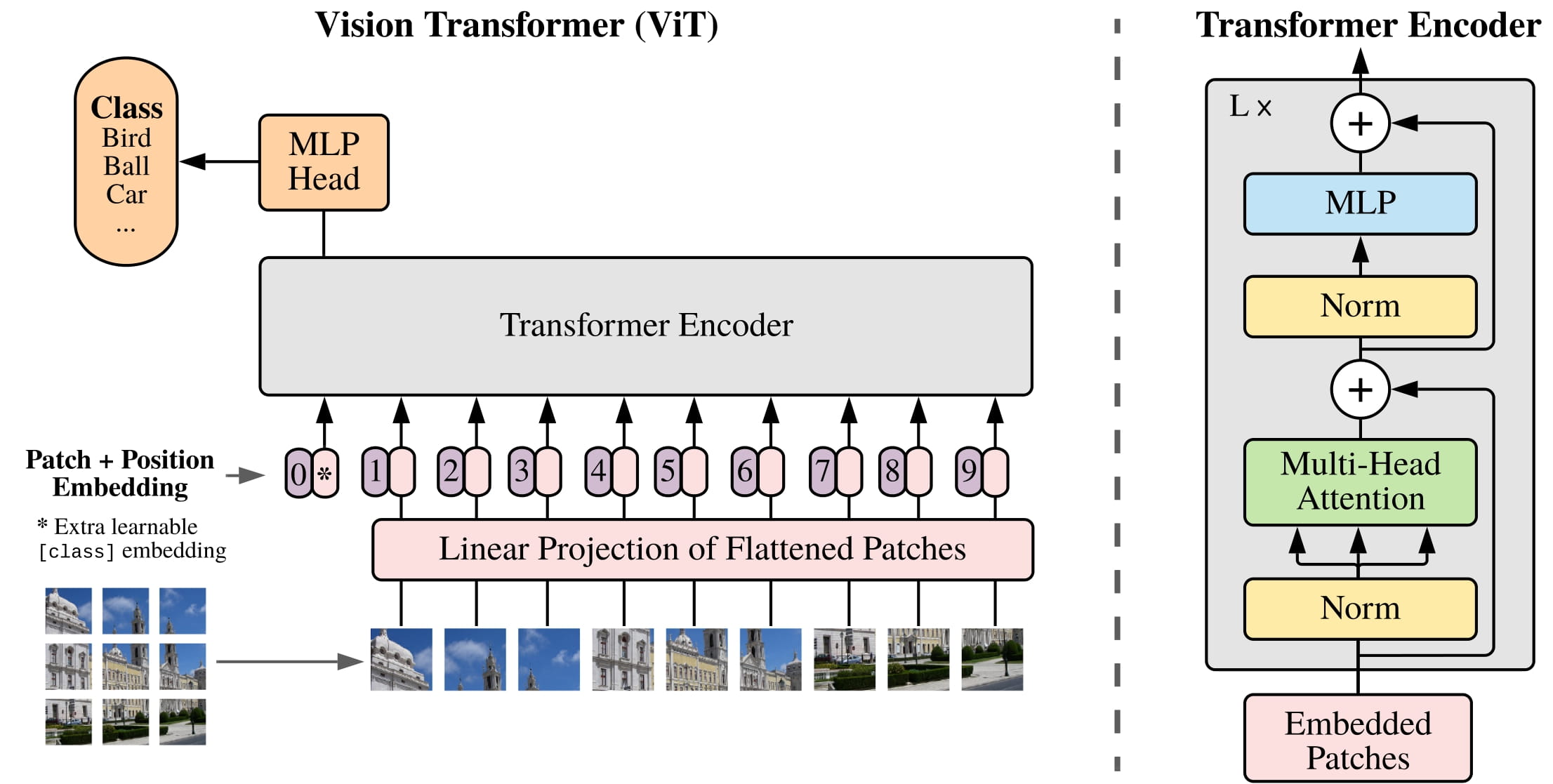
Patch embedding을 통해 만든 196개의 (1, 768) 크기 vector들은 encoder를 통과한다.
ViT와 NLP transformer들의 encoder는 구조와 동작 면에서 거의 같다.
Patch embedding을 모두 concat하여 (196, 768) 크기의 input을 만들고 transformer encoder에 넣었을 때, 동일한 (196, 768) 크기의 ouput이 나온다.
MLP Head
MLP head에서는 encoder의 결과를 갖고 최종적으로 classify를 하게 된다.
Transformer encoder의 output으로 (196, 768) 크기의 데이터가 나왔을 때, 첫 번 째 차원에 대해 mean을 구해 (1, 768) 크기의 vector를 만든다.
이 벡터에 (768 $\rightarrow$ number of classes)로 매핑하는 fully connected layer를 연결하여 최종적으로 (1, number of classes) 크기의 output을 만들어낸다.
Inductive Bias
위에서 설명한 Vision Transformer의 구조는 CNN과는 달리 이미지에 특화된 inductive bias가 적다.
CNN에서는 인접 픽셀 간의 정보를 잘 추출해내므로 local한 영역에서 spatial information을 잘 찾아낸다고 알려져 있다 (locality).
또한, CNN은 이미지 내의 객체, 패턴 등이 이동함에 따라 feature map의 결과도 달라지게 되어있다 (translation equivariance).
그러나 Vision Transformer에서는 MLP layer들만 local, translationally equivariant의 inductive bias를 담고 있다.
또한, ViT의 학습 초기의 position embedding들은 2차원 위치에 대한 아무런 정보도 없기에 patch 간의 spatial relation을 학습하는 데 시간이 걸린다.
왜 16x16 크기의 패치를 사용할까?
Vision transformer에서는 작은 크기의 패치를 사용할수록 패치의 개수가 늘어나기에 computational cost는 적당하면서 좋은 성능을 나타낸 16x16이라는 크기를 사용한다고 한다.
Patch 크기가 작을수록 성능은 좋아지는 경향이 나타난다고 한다.
그러나, self attention의 시간복잡도는 $O(n^2d)$이므로, n (patch 개수)이 커지면 computational cost가 크게 증가하게 된다.
따라서 vision transformer에서는 computational cost는 적당하면서도 좋은 성능을 나타낸 16x16이라는 크기를 사용한다고 한다.